C:技術で/技術が/技術を(ICT:社会・法・制度論と技術文化論)
●今、振り返る インターネットの歴史 - Yahoo! BB http://bbpromo.yahoo.co.jp/special/history/
たとえば1995年はというと、「Windows95」発売/「InternetExplorer 1.0」公開/日本初のアダルトサイトが登場/「テレホーダイ」サービス開始/PHSサービス開始/キーワード型検索サービス「InfoNavigator」の開始/ロボット型検索サービス「ODiN」開始/Searcher in Wasedaが「千里眼」に名称変更。
2005年は、「YouTube」サービス開始/「Yahoo!ブログ」サービス開始/ブロードバンド放送サービス「GyaO」開始/個人情報保護法の全面施行/イー・モバイル株式会社(現・ワイモバイル株式会社)が設立/「はてなブックマーク」サービス開始/「のまネコ」商標登録騒動が勃発。
(歴史: インターネットの主な出来事 1995-2015 http://bbpromo.yahoo.co.jp/special/history/chronology/ )

●Windowsの変遷を画像で振り返る--「Windows 1.0」から「10」まで http://japan.zdnet.com/article/35067916/
30年にわたる「Windows」の歴史。Windows(当初の開発コード名は「Interface Manager」)の出荷が開始されたのが、30年前の1985年11月20日。
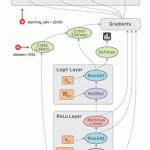
●Google、ディープラーニングをサポートした機械学習ライブラリ「TensorFlow」をオープンソースで公開 http://www.publickey1.jp/blog/15/googletensorflow.html
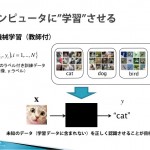
脳の活動を模したニューラルネットワークによって学習を実現する「ディープラーニング」をサポートした機械学習ライブラリ「TensorFlow」。
●歴史が動いた!GoogleがAIを公開した理由 http://thewave.teamblog.jp/archives/1044710535.html
Googleはもはや検索エンジンの会社と形容すべきではなく、AIの会社と形容されるべき。
さてそのGoogleが、オープンソース・ソフトウェアとしてTensorFlowと呼ばれるアルゴリズムを公開した。Googleの画像認識や、音声認識、翻訳、メール分別、自動返信、広告など、Googleのほとんどのサービスに利用されているAIだ。
競争力の源泉たるそのエンジンを公開するのは、AIはデータの「量」が進化の鍵を握るからだ。たとえば、「Facebookの顔認識AIが米軍のAIよりも認識精度が高いのは、Facebookの方が顔写真データを大量に所有しているから」。

●「女子高生AIりんな」は気づかいのできる人工知能娘だった http://ascii.jp/elem/000/001/079/1079132/
Windows 10に搭載されたパーソナルアシスタントの「コルタナ」はマイクロソフトのAI技術開発のひとつの成果。そして、「女子高生AIりんな」も。

ふたつが相立ち並ぶのにはわけがある、「コルタナは、(略)プロダクティビティ(生産性)向上のためのものだ。一方で、りんなは『ソーシャルフレンド』として、ユーザーとの感情的なつながりを持つことを目指している」。「寂しくないSNS」実現のために、「りんな」は開発された。
ユーザーが飽きずに長続きする会話の秘密は「知性のマイニング」。背景にあるのが膨大なデータ量。「インターネット上のWebサイトやSNSには、人間どうしのチャットや会話のデータが大量に存在する。シャオアイス/りんなでは、パブリックデータ化されている会話データを収集してデータベース化し、そこから「適切な応答」をマッチングさせている」。

●東京大学工学系研究科 准教授 松尾 豊「人工知能の現在と未来」 http://www.soumu.go.jp/main_content/000340305.pdf
「ビックデータはある種の目の誕生と同じで、人工知能は脳の発達(抽象化能力の向上)と考えられる」「抽象化と通信はほぼ同じ。これに、IoT、分散されたインテリジェンスが加わる」ことで、「体の知能を超えて、ネットワークを介した社会全体の知能化」が展望される。
一方、「シンギュラリティの議論で最も重要な点として、コンピュータの知能のレベルがどこまで上がるかという話と、それが本能を持って生命としての欲望を持つかということは、分けて議論しなければならない」「コンピュータが自らを超えるものを作り出していくというシナリオを考えることは難しい」。


●「Internet of Thingsを加速する新しいコンピューティング」 http://www.soumu.go.jp/main_content/000346583.pdf
ビッグデータの登場は人工知能との関係では「量」の面で朗報だが、「質」の面で新たな壁となる可能性がある。
ひとつにはデータの多様性を整理する工程が必要になるからだ。「データサイエンティストが増えるスピードよりも、はるかに速いスピードで増大していくので、人的資源の不足が大きな問題」だが、ここで逆にディープラーニングの技術(人工知能)革新が問題解決の鍵をにぎってているかもしれない。
もう一点、これらのデータはクラウドに送るにはコスト的に引き合わない(価値密度が低い可能性)からだ。この課題を解決するために、IoTの先端、エッジ、端末側にディープラーニングさせるということが起きるかもしれない。
●ネクスト、「HOME’S」の賃貸物件データを研究用に無償提供 http://japan.zdnet.com/article/35073651/
HOME’Sに掲載された全国約530万件の賃貸物件データと、その間取り図や室内写真など約8300万枚の物件画像データを、研究目的であれば大学などが自由に使えるようにした。
●情報学研究データリポジトリ データセット一覧 http://www.nii.ac.jp/dsc/idr/datalist.html
「HOME’S」の賃貸物件データの「オープンデータセット」化は、国立情報学研究所との連携で実施されたが、同研究所はすでに多くのデータセットをオープン公開している。
![]()
●オープンデータセット | 国立国会図書館-National Diet Library http://www.ndl.go.jp/jp/aboutus/standards/opendataset.html
国立国会図書館もオープンデータセットを展開中。「このサービスで利用できるデジタル化資料(図書・雑誌・古典籍)について、原資料の基本的な書誌項目(タイトル、著者、出版者など)とデジタル画像の書誌項目(URL、公開範囲)をデータセットで提供」。
●オープンデータ活用事例から見出す新たなビジネスの可能性 http://www.jipdec.or.jp/library/report/20151111_02.html
オープンデータの流れは、2013年にオープンデータ憲章により「税金を使って作られたデータはすべて公共財として公開するべきである」という考え方が採用されて急速に進んでいる。
●デザイナーたちは、仕事にiPadをつかっていない:調査結果 http://wired.jp/2015/11/11/sorry-apple-turns-out-designers-dont-use-ipads/
データ、データ、データのWeb世界だが、身体性ゆえか「デザイナーたちは、仕事にiPadをつかっていない」。一枚の紙と鉛筆は、やはりあるプロセスで他に代えがたい魅力があるのかも。

●東京大学先端科学技術研究センター 教授 森川 博之「あらゆるものごとの『データ化』とその利活用の展望」 http://www.soumu.go.jp/main_content/000351980.pdf
ユーザ企業でのICT 技術者に必要なこと=デザイン能力が求められる。
デザイン能力とは「気づく」・「考える」・「試す」・「伝える」能力で、特にこれから求められるのが「気づく」能力と「伝える」能力」。
「農業にしてもシビルエンジニアリングにしても水道系にしても、そういった人たちにICT、IoT を使うと、こんなことが可能になるのだということを伝えられる「気づく」能力と「伝える」能力の両方を兼ね備えていかなければいけない」。
●「これは合成ではない」Magic Leap、最新AR技術の動画を公開 https://wired.jp/2015/10/22/magic-leap-augmented-reality/
「OculusのようなVR(仮想現実)ではなく、Microsoft HoloLensのようなAR (拡張現実)型のインターフェイスを持つハードウェアを利用し、現在は一部デベロッパーとの間で秘密裏にアプリケーション開発を進めている段階。

●最先端の技術VRは、自由意思でどこにでも"移動"ができる http://time-space.kddi.com/digicul-column/world/20151111/index.html
「従来のVRでは、周りを見渡せば視界が変わるものの、稼働することはなかった。しかし「CableRobot Simulator」は、行きたい方向に操れば自身もxyz軸すべての方向へと移動できるようになる」。

●ネットにある無数の写真から街の3Dモデルを生成、Googleがコンピュータービジョンの最新技術を披露 http://internet.watch.impress.co.jp/docs/news/20151110_729848.html
「インターネット上にアップロードされた膨大な写真を使って、イタリアのトレヴィの泉など、観光名所を3Dモデル化できないか」。
写真の自動マッチングシステム、それは、撮影された位置や方向を写真から識別でき、写真をテクスチャとして継ぎ接ぎできる。そのシステムを使い、ローマの写真100万枚をデータセットとして市全体のモデル化に挑んだ。500台程度のコンピューターを使用し、1日でローマ市全体を3Dで再現。
(Jump – Google https://www.google.com/get/cardboard/jump/ )



●グーグル勝訴で浮き彫りになるフェア・ユースと著作権の問題 http://magazine-k.jp/2015/10/29/google-books-wins-over-the-authors-guild/
Q:「なぜ著作権というものがあって、それを法律で保護するのか」。
Ans:公益=「すべての人々が知の恩恵を受けられるように、何かを生み出した当人の著作権を認めてその知を広める」ため。
グーグルはあくまで、「デジタル時代にふさわしい新しい図書カードシステムを作ったのだ、と考えている」。
●TPPで“違法ダウンロード”適用拡大も、文化庁の審議会で再び検討か http://internet.watch.impress.co.jp/docs/news/20151111_730105.html
「違法にアップロードされた音楽や映像であることを知りながら、それをダウンロード(自動公衆送信を受信して行うデジタル方式の録音又は録画)する行為は、2009年6月の著作権法改正により、私的使用のための複製としては認められなくなり、違法となった(いわゆる“ダウンロード違法化”、施行は2010年1月)」。
「さらに2012年6月の著作権法改正によって、有償著作物の違法ダウンロード行為に対して罰則が設定された(いわゆる“違法ダウンロード刑事罰化”、施行は2012年10月)」。
●TPP交渉で知財分野は日本の完敗だった http://www.videonews.com/marugeki-talk/759/
「著作権分野の重要3点セットと呼ばれ、ここまでの交渉で日本が反対してきた「著作権保護期間の70年への延長」、「非親告罪化」、「法定賠償制度の導入」の3点はいずれも今回の大筋合意に含まれてしまった。
福井氏は著作権を含む知的財産分野では、アメリカが求めていたもののほとんどすべてが入っていると指摘する。甘利氏が胸を張る「日本にとっての最善の結果」という評価には、どう考えても首を傾げざるを得ない」。
●超ざっくり! TPP著作権問題の現在地点 http://internet.watch.impress.co.jp/docs/special/fukui/20151019_726249.html
「「保護期間延長すればバーターで解消できる」と盛んに喧伝された戦時加算( http://digital.asahi.com/articles/ASH7R67GKH7RULFA038.html )だが、当然ながらTPP条文のどこにもそんな記載はない。今後の二国間交渉に委ねるのだろうが、ああいった情報を振りまいた個人や団体は当然、最後までちゃんと責任を取るべきだ」。
ただし、「米国1国でもTPPに署名できなければ、当然話は振り出しに戻るだろう」というのが結構可能性として高いのでは。