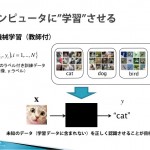
C:技術で/技術が/技術を(ICT:社会・法・制度論と技術文化論)
●Google、人工知能ライブラリ TensorFlow をオープンソース化。 http://japanese.engadget.com/2015/11/09/google-tensorflow/
グーグルが音声検索や写真認識、翻訳の基盤技術ディープラーニングを商利用可で解放。
「TensorFlow の原型は、Google社内の機械学習やディープニューラルネットワークの研究者・エンジニアが開発してきたソフトウェア群。機械学習以外にも応用できることなどから、GoogleではTensorFlow を「機械知能 (マシンインテリジェンス)のためのオープンソース・ソフトウェアライブラリ」と呼んでいる。
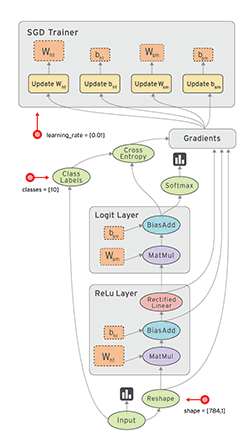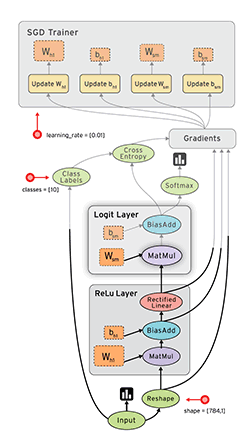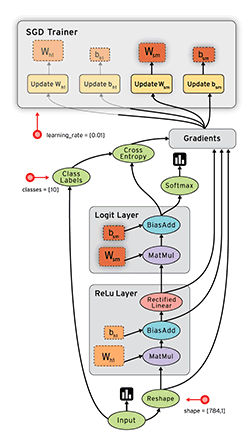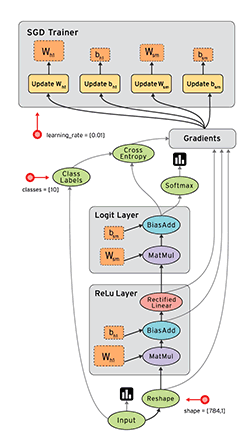
●グーグル、機械学習システム「TensorFlow」をオープンソース化 http://japan.zdnet.com/article/35073215/
商用利用が可能なApache 2.0ライセンスで公開しているため、個人から他社まで使用できる。グーグルとしてはこれにより機械学習の普及を推進し、コミュニティを活性化したい考え。
分野は違うものの、Android をオープンソース化提供することでモバイルコンピューティングの普及を加速させ、結果的にはGoogleのビジネスにとって有利な状況を作り出した、その戦略そのまま。

●学習する人工知能がGmailの返信を考えてくれる「Smart Reply」 http://www.gizmodo.jp/2015/11/gmailsmart_replyinbox.html
グーグルが開発した「Smart Reply」は、ニューラルネットワークを使って、読み込ませたメールの返信案を自動生成してくれる。返信案は3案。気に入ったものを選ぶもよし、必要なら手直しするもよし。

●スマホの文字入力アプリ「SwiftKey」、ニューラルネットワークで恐ろしいほど賢くなる http://www.gizmodo.jp/2015/10/swiftkey.html
日本のケータイ、スマホで当たり前の入力文字の予測変換。その予測候補の引き出し方について。
これまでは過去の入力履歴に頼っていた。これをSwiftKey Neural Alphaは、同じような言葉の塊(クラスター)に着目。似たような役割の言葉たちを一つの塊ととらえ、同じ群の他の言葉に置き換え可能だと判断して、ユーザが一度も使ったことのない単語でも候補として提示できるようになった。

●日本人は空気読むから?AI予測変換で世界各国に周回リード http://www.keyman.or.jp/at/30008024/
日本語は表音文字のひらがなと表意文字の漢字からなる言語であるため、パソコンのキーボードでまずローマ字入力やひらがな入力でかな文をタイプし、その一部を漢字に変換するという処理法を進化させてきた。
その進化の過程のある時点から、文脈に応じて適切な漢字候補を表示するだけでなく、文字列を途中まで入力した時点で、それに続く文章までも漢字変換して提示してくれるようにもなった。
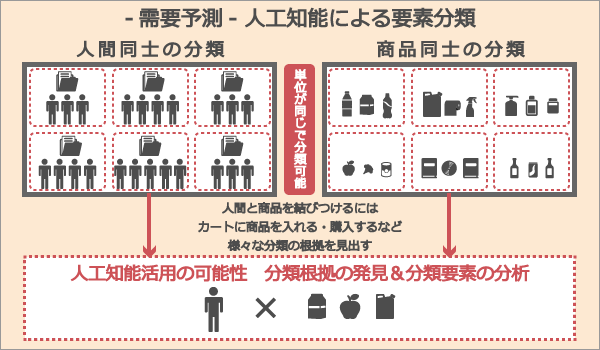
●人工知能と要素分類【ECのミカタ】 http://ecnomikata.com/ecnews/marketing/6649/
最も単純な「Aを買っている人はBも買っている」という、いわゆる相関によるレコメンド(=協調フィルタリング)というのは購買行動を要素として商品同士を分類している。
実は人工知能も機械学習も要素をみつけて分類する、という作業を行っている。ただし人間と商品は単位が違うため、そのまま演算ができない。それらを結びつける要素、ラベルとかメタデータといったものが必要になってくる。
これから重要なのは、こうしたラベルやメタデータをどう扱うか、という点。
●人工知能搭載キャラクター「ヨコかな?」 http://prtimes.jp/main/html/rd/p/000000002.000016039.html
人工知能搭載キャラクター「ヨコかな?」は、人間の声や入力に反応し、人工知能によって自由に会話ができる「感情」を持った絵文字キャラクター。(サイト:http://yokokana.com/ )
特徴: 「文字」をモチーフにした動くキャラクター/人工知能を搭載して、自由に会話ができるキャラクター/映像や知育グッズなどメディアミックスしたキャラクター展開。



●すべてがUIになるVRの世界 : could http://www.yasuhisa.com/could/article/everything-ui/
スマートウォッチをはじめとしたウェアラブルや IoT の登場によって、従来のような GUI を前提としたインタラクションデザインではなく、NO・GUI のデザインが注目され始めている。しかし「NO」の向こうに、everything、という発想があるのではないか。つまり、「Everything UI」の世界観。
日用品や建築など、すべてが UI になりえる/スクリーンという領域や形状が制約でなくなる/固定位置にあるものではなく、私たちと一緒に動き出す/ジェスチャーだけでなく、視線や脳波もインプットになる。
●グリー、バーチャルリアリティコンテンツ市場参入へ、「GREE VR Studio」を設立。 http://readwrite.jp/archives/25958
2020年にはVR関連ビジネスの売上高が300億ドル(3.6兆円)になるとの予想。「今後はVR市場の成長に合わせ、ゲームのみならず、映像や体験型コンテンツなど広い領域での開発を手がけてい」く。

●もはや実写!?最新CG技術で制作されたデジタルヒューマンがすごすぎる http://thecast.jp/archives/139
「動画の中では、女性が話している様子やこちらを振り返っている様子など、様々なシーンのデジタルヒューマンを見ることが出来る。肌の質感やしわ、微妙な口・目の動きなど、あらゆる面で本物の人間に近い、もしくは見間違えるようなリアリティが表現されている。パッと見ただけではどこからが人間でどこからがCGか分からないほどのリアルさ」。

http://www.dexterstudios.com/digital/en_rnd.asp?id=11
●21世紀はデータが経済の「血液」になる 個人データは自分で管理 http://thewave.teamblog.jp/archives/1039565349.html
データを「経済の血液」にするには、異なる企業、組織間でデータを交換、共有する仕組み作りが必要だが、これが簡単ではない。
ひとつの解がパーソナル・データ・ストア(PDS)と呼ばれる概念=個人情報や購買履歴、SNSの投稿履歴など、ありとあらゆるデータを、個人側でも管理するという考え方。
東京大学の橋田浩一教授はこの分野の第一人者のひとりで、教授が研究しているのは「PDSの中でも特に「分散PDS」と呼ばれるもので、個人が特定の事業者に依存せずに運用できるPDS」。
●IPA 「共通語彙基盤」 セミナー 備忘録 http://blog.code4osaka.org/2015/09/post-164/
リンク集。共通語彙基盤とは政府や地方自治体が公開するオープンデータにおいて用いられる語彙集。同じ事柄に対する用語が各機関によって異なる状態では、統計データの集計や情報交換に支障が出るため、共通で使用するための語彙をまとめたもの。ビッグデータとその解析を効率よく行うためにはこのようなインフラが必須。
●総務省、IoT向けに「020」番号を割り当て。携帯向け「060」は見送り http://japanese.engadget.com/2015/10/19/iot-020-060/
IoTとは物と物とが通信しあう世界。当然電話番号が必要になる。現在、携帯電話には「090」「080」「070」で始まる番号が割り当てられているが、その数がそろそろ天井に近づいている。そのためIoTのための新たな番号体系が必要とされていた。総務省は番号をこれまでより2桁多い13桁とすることで、約80億件の番号を揃えた、としている。
●日本の“行政Tech”が世界の注目を集めた日~GitHub Universeに登壇した国土地理院・藤村英範氏が語るオープンデータの取り組み http://engineer.typemag.jp/article/hfu
国土地理院では、全国で測量した地形図データをはじめとした地理空間情報をいろいろな形で利用してもらえるよう、インターネット上に2003年からWeb地図『地理院地図』を公開。
「もちろん、災害対応以外にもビジネスや商用でもデータを活用できるように公開されています。データの応用範囲を広げるために、3Dデータを3Dプリンタで出力しやすい形で公開したり、地図が簡単に作れるようにしたりしている例を挙げ、実物のサンプルを見せるなどして分かりやすく説明した」。(資料: https://speakerdeck.com/hfu/ )

●暦本純一が選ぶ「テクノロジーと拡張する人間」を考えるための5冊 http://wired.jp/2015/10/20/xreaders_junichirekimoto/
『文明学の構築のために』梅棹忠夫/『テクニウム──テクノロジーはどこへ向かうのか?』ケヴィン・ケリー/『サイボーグとして生きる』マイケル・コロスト/『ソラリス』スタニスワフ・レム/『オートメーション・バカ─先端技術がわたしたちにしていること─』ニコラス・G・カー。